This is a course project for the “Machine Learning at Scale (W261)” class at UC Berkeley’s Master in Data Science program. The project team included Erik Sambrailo, Bailey Kuehl, Lucy Herr, and Artem Lebedev. All authors contributed equally. Project GitHub repo. Read the full story on Medium.
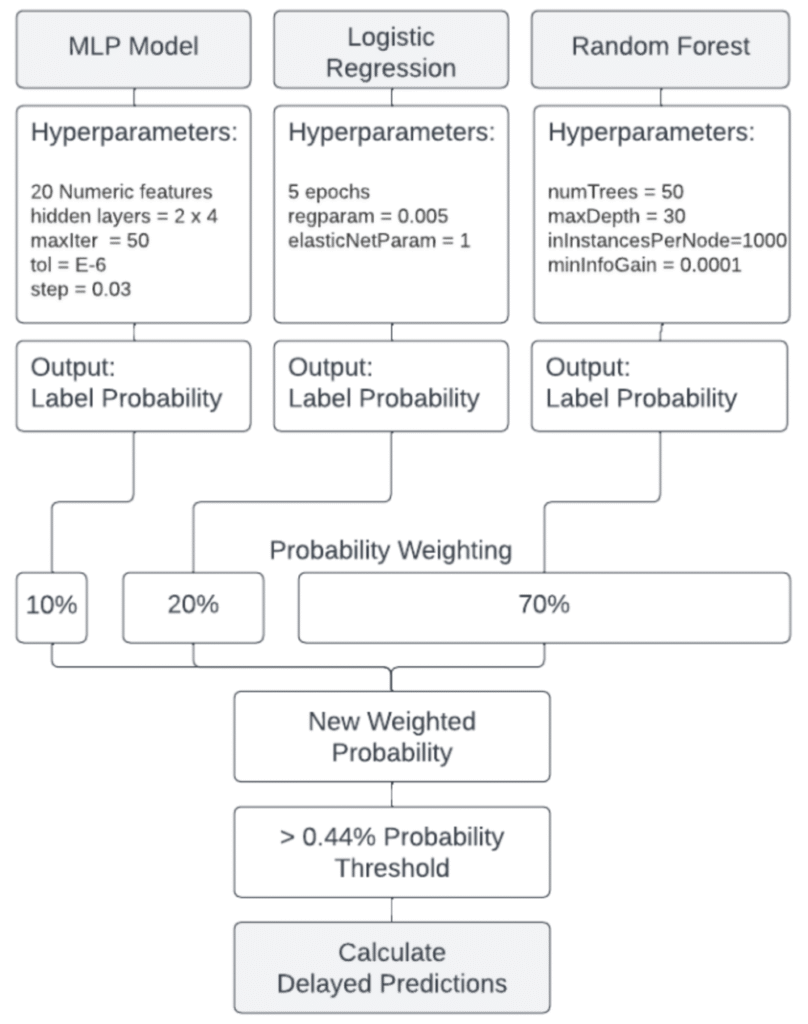
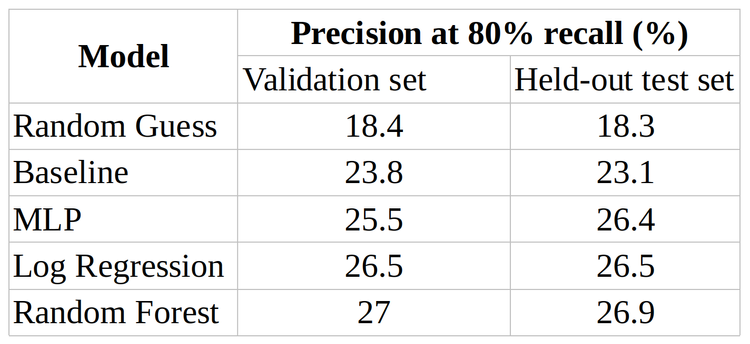
The goal of this project was to develop proficiency in processing large distributed datasets using Spark framework and MLlib libraries. To that end, we were tasked to predict, 2 hours before the departure, whether a flight would be delayed. The flight information dataset included detailed records of over 30 million flights with data volume exceeding 150 Gb. To process such a large dataset, we employed a 40-core cluster managed by Databricks and stored data in Azure blob storage. Extensive EDA and ETL pipelines had to be developed to eliminate inconsequential features and join disconnected datasets into a single parallelized data frame. With the joined dataset in hand, we compared logistic regression, random forest, and multilayer perceptron (MLP) models. Precision at 80% recall was chosen as a performance metric over traditional F1 and F2 scores because of its relevance to business decisions. Finally, we combined these models to create an ensemble, which demonstrated 26.5% precision at 80% recall on the test dataset. This is only a modest improvement over a random guess that would result in 18% precision at 80% recall, likely, due to the lack of data on the aircraft maintenance. The winning pipeline was a result of fine-tuning the hyperparameters within each respective model and included engineered features, such as average delay at the origin airport, latest known delay of the aircraft, etc. Special precautions were taken to avoid data leakage in this time-series modeling.
Keywords: Spark, Hadoop, MLlib, Random Forest, Logistic Regression, MLP, Databricks, Azure, Time Series
Keywords: Spark, Hadoop, MLlib, Random Forest, Logistic Regression, MLP, Databricks, Azure, Time Series